
This blog post will be a review of the Global Data Summit. But first I would like to lose a few sentences about the Advanced Data Vault & Ensemble Modelling meeting, organized by Hans Hultgren and Remco Broekmann. It is an event that brought together experienced data modelers from all over the world (New Zealand, South Africa, Europe and the USA) around Data Vault, Focal and Ensemble Logical Modeling (ELM). That sounds promising, doesn't it?
Advanced Data Vault & Ensemble Modelling
There were two interesting days with many topics around Data Vault and ELM, which were put up for discussion. The idea behind the meeting is to think further, e. g. where to go with Data Vault and ELM and what the participants can contribute from their own experiences. I personally find some of the points discussed very interesting and exciting and should be pursued further. With others I have to go into myself and continue researching. Most likely, I'll go into other blog posts on different topics, such as the discussion about concatenated key, partitioned links or how you can do without satellites on links. I will see.
For me personally, the intensive exchange with other participants such as Patrick Lager, Dani Schnider or Sander Robijns (to name just a few) during the breaks, in the evening and already in the morning at breakfast was unbelievable. Due to this and the large number of topics, we spontaneously organized an extra meeting on Sundays to discuss and exchange ideas about bitemporal data in Data Vault. Hans asked me beforehand to lead the discussion. These were a few very intensive hours in which we were immersed from general bitemporal aspects to more complex details.
International meeting of Data Vault minds in Colorado! #datavault #advanceddatavault @gohansgo @RemcoBroekmans pic.7905d1c4e12c54933a44d19fcd5f9356-gdprlock/F68lIDUU44
— Genesee Labs Cowork (@GeneseeLabs) 28. September 2017
Global Data Summit
On Monday, the Global Data Summit in Golden, Colorado began. On Twitter you can follow the Twitter feed at #GDS17. Stephen Probst was supposed to start with his key note Next Generation of consumer intelligence - The quantified self, but he was stuck in traffic in Coloroda. What was interesting about the key note was that CRM will have to change into a vendor relationship management (VRM) system in the future, as customers are now very sensitive to too much advertising via e-mail etc.
Probst sees business intelligence as an enabling technology, because the data warehouse already stores all data about us, the Quantified Self: books we have read, music we have read and much more from our everyday life.
I find it interesting that within the framework of the VRM, companies should also accept terms and conditions of business with regard to the use of our data, and not, as is the case today, only the unilateral stipulation of company terms and conditions.
As a European, the not unrealistic prospect of The Quantified Self is, in my view, worrying. So, justifiably, on the #GDS17 much was discussed about GDPR, which protects us as a person and gives us the right to return our data.
 The first presentation of the day was given by Jaco van der Laan about the Data Vault project at Rabo Bank in the Netherlands. Jaco illustrated how complex a data warehouse can be in terms of business keys, timelines and integration when many other upstream data warehouses are the source of the data. Beside some performance tuning tips, the quintessence of the lecture was that a good data architecture is the success criterion, e. g. by getting the data directly from the original sources.
The first presentation of the day was given by Jaco van der Laan about the Data Vault project at Rabo Bank in the Netherlands. Jaco illustrated how complex a data warehouse can be in terms of business keys, timelines and integration when many other upstream data warehouses are the source of the data. Beside some performance tuning tips, the quintessence of the lecture was that a good data architecture is the success criterion, e. g. by getting the data directly from the original sources.
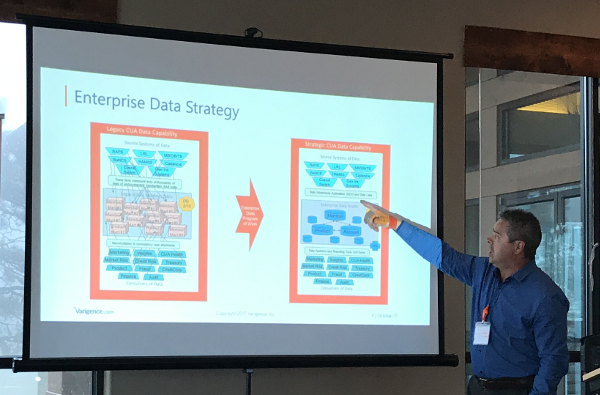 Another exciting lecture of the first day was given by Damian Towler of CIS from Australia. Starting from the unsustainable situation with flat files, hand-written ETL and non-existent standards, CIS introduced a data strategy with an Enterprise Data Strategy, Data Vault and the automation of ETL as its goal. The presentation focused on the goal-oriented and transparent procedure for selecting a data warehouse automation tool.
Another exciting lecture of the first day was given by Damian Towler of CIS from Australia. Starting from the unsustainable situation with flat files, hand-written ETL and non-existent standards, CIS introduced a data strategy with an Enterprise Data Strategy, Data Vault and the automation of ETL as its goal. The presentation focused on the goal-oriented and transparent procedure for selecting a data warehouse automation tool.
Between the talks, the #GDS17 offered plenty of opportunities for networking and sharing, as well as the 5x5 presentations: 5 slides in 5 minutes to explain a topic.
One of these 5x5 presentations I gave myself was about transforming bitemporal data from the Data Vault into a bitempered star schema (see also my previous blog post). I can only say that five minutes are not really long!
 The second day of the #GDS17 was opened by Rick van der Lans with his key note Data: From the Cellar to the Consumer. The fact that today's data are no different from 20 years ago, only more of it, is an interesting thesis.
The second day of the #GDS17 was opened by Rick van der Lans with his key note Data: From the Cellar to the Consumer. The fact that today's data are no different from 20 years ago, only more of it, is an interesting thesis.
It is also interesting to note that the data from the cellars of the data centers are much "closer" to the users of the data. Years ago, many employees and specialists were still needed to prepare, make use of and pass on data, but nowadays, even in the public sector, it is possible to retrieve their data directly via the Internet. Rick van der Lans cited an example from the Netherlands, where you don't have to go to the doctor any more, but can retrieve the results of your blood test directly from the web.
For companies, data is becoming a key business asset rather than a simple by-product, and Rick van der Lans asks the question: Is your company ready for the battle of data? Is the value added from data already high enough or is it still strongly focused on production with high material and personnel input?
Rick van der Lans concludes: The question is not about new technology for business intelligence but instead what and how to do with data -> Data First!
Matt Fornito spoke in his lecture about the possibilities of neural networks, including in medicine. One example was the coupling of 13 neural networks to detect melanomas in the face.
Afterwards Daniel Fagerström made an impressive demonstration of how it is possible to load real-time, high-volume streaming data from online gaming directly into Data Vault. With Kafka and KSQL this works well and fast. Really interesting, what is possible here!
Patrick Lager gave us exciting insights into the project's everyday life. The everyday problems that a data warehouse project has to contend with over the years: e. g. great ideas of management: Hey, I've heard about BigData (Hadoop), I want to have that now and we can replace the database with it! It's nice to hear how the project dealt with it. Patrick Lager's summary is as simple as it is plausible and often difficult to implement:
"Before starting with a new tech, e. g. Hadoop, put it on the side for some time, learn it and make some experience.”
It’s easier to get ETL developer than good data modeler. You have to educate them says @PatrikLager #GDS17 pic.7905d1c4e12c54933a44d19fcd5f9356-gdprlock/tshdFsIwyv
— Dirk Lerner (@DV_Modeling) 3. Oktober 2017
In the Panel Data Vault Modeling 2020 Patrick Lager, Torsten Glunde, Remco Broekmanns and Dirk Lerner (that's me ;-) ) discussed the following questions, among others (the answers are briefly summarized):
Q: What do you think how Data Vault will look like in 2020 or Data Modeling for Data Warehousing in 2020?
A: The logical and conceptual Medlierung werden einen größeren Anteil an der Auf gabe eines Datenmodellierers haben.
Q: How will temporal (data) aspects influence modeling?
A: There was an intensive discussion, but no conscence in the Panel. I’m personally think it will become an important part everywhere in Data Warehousing!
Q: What changes can we expect in Data Vault?
A: There will be changes, driven by a broader community driven by real world needs. Let’s see what happens in the next years!
For me it was an exciting conference. I was very pleased that Hans invited me and it was an honour to lead the Panel Data Vault and participate as an expert!
#GDS17 Ensemble Modeling in 2020: much more focused on logical models, not so much the technical implementations. pic.7905d1c4e12c54933a44d19fcd5f9356-gdprlock/IZs95v01dT
— Marc Bouma (@marc058) 3. Oktober 2017
The BI Boulder Brain Trust (#BBBT)
On the evening of the second day, Claudia Imhoff, all #BBBT members present at the conference, invited everyone to a first dinner together. This was the first time ever, as never before have so many international members come together in one place. It is great to be able to see and greet the many people, who are familiar with time (although virtual), in real life.
FINALLY! A #bbbt dinner with local & international members. I am SO proud of every member. You all rock!! pic.7905d1c4e12c54933a44d19fcd5f9356-gdprlock/hWeVPTK78T
— Claudia Imhoff (@Claudia_Imhoff) 4. Oktober 2017
At the end
The whole week was very interesting with a lot of great impressions. I can say for myself that it was worth it and I come back to Germany with a lot of inspiration.
And while I'm on the plane back home, I'm happy that the engine still works (it didn't want to start), I write the last few lines of this blog post and enjoy the whisky, because the nice board staff recommended it to me.
So long,
Dirk
P.S.: My good friend Dani Schnider has also published a blog post to #GDS17. Check this one out, too.
P. P. S: Peter Avenant has also published a blog post on this subject.